Como funcionam as linguagens de programação?
por Sérgio Henrique Miranda Júnior em 31 Dec 2015
Os computadores controlam grande parte do que acontece no mundo hoje. Esse controle abrange desde de sistemas computadorizados, que controlam leitos de hospitais, monitorando a situação dos pacientes que estão ali, até usinas nucleares utilizadas para gerar energia. Outro exemplo mais próximo são os carros que dirigimos: grande parte de sua montagem é feita por máquinas computadorizadas e, depois de pronto, o controle das partes elétricas fica a cargo dos sistemas embarcados. Enfim, os computadores são responsáveis por manter o funcionamento de uma quantidade enorme de processos que foram desenvolvidos pelo homem ao longo dos anos. Mas como o computador é capaz de controlar os diversos tipos de processos que existem? Basicamente, o homem desenvolve inúmeros tipos de softwares que são capazes de realizar o que foi programado. Sendo assim, vamos entender como um software é escrito e como ele é entendido por um computador. Para facilitar o entendimento, todo o processo será ilustrado com a criação de uma linguagem de programação fictícia, chamada 'Caipires' (pode ser encontrada aqui). Essa linguagem será construída utilizando os recursos providos pela linguagem de programação Ruby.
Assim como nós utilizamos o português como linguagem para desenvolver nossos textos, nós precisamos de uma linguagem de programação para desenvolver software. Dessa maneira, o caminho que é percorrido desde a escrita do programa até a sua execução pelo computador aborda os seguintes tópicos: (i) Análise Lexica, (ii) Parser, (iii) Runtime, (iv) Interpretador, (v) Máquina Virtual, (vi) Compilador.
Análise Léxica
O trabalho do Lexer é ler uma cadeia de caracteres e gerar significado a cada conjunto encontrado, que são chamados de tokens. De maneira resumida, ele extrai as palavras do seu programa e da um significado a cada uma delas (tokens) para serem processadas posteriormente pelo Parser. Suponha o seguinte programa em 'Caipireis':
falaso("Programa de teste")
O programa acima, após ser analisado pelo Lexer, produzirá a seguinte saída (de acordo com a regras da linguagem 'Caipires'):
[[:IDENTIFIER, falaso], ['(', ')'], [:STRING, 'programa de teste'], [')', ')']]
Para cada palavra encontrada pelo Lexer ele gera um array onde a primeira posição é o significado da palavra e a segunda é o valor encontrado.
Dessa maneira, temos:
(i) a cadeia de caracteres 'falaso' foi identificada como um IDENTIFIER pelo Lexer ([:IDENTIFIER, falaso]), que na nossa linguagem Caipires pode ser o nome de uma variável, de um método ou de um parâmetro formal;
(ii) o caracter ( não tem um nome específico, por isso foi gerado como nome e valor a sua própria representação (['(', ')']);
(iii) a cadeia de caracteres 'programa teste' foi reconhecida como uma STRING ([:STRING, 'programa teste']);
(iv) e por último, o caracter ) é análgo ao caracter ( encontrado anteriormente. Sendo assim, o Lexer cumpriu sua tarefa de ler uma cadeia de caracteres e gerar significado quando um conjunto de caracteres assume um valor possível dentro da linguagem de programação.
Não é difícil implementar um Lexer, basta conhecer um pouco sobre expressões regulares. Existem ferramentas que facilitam o trabalho de implementação. Um exemplo é o Rexical, uma implemetação em Ruby que segue o estilo do Lex. Geralmente essas ferramentas esperam como entrada uma gramática que será compilada em um Lexer. O formato dessas gramáticas são semelhantes: expressões regulares na esquerda e ação a ser tomada na direita. Um exemplo de gramática para analisar a cadeia de caracteres do código mostrado anteriormente poderia ser o seguinte, levando-se em conta a utilização da ferramenta Rexical:
rule
\"[^"]*\" { [:STRING, text[1..-2]] }
[a-z]\w* { [:IDENTIFIER, text] }
. { [text, text] }
A primeira expressão regular considera como uma string toda a cadeia de caracter que começa com " e é seguida por zero ou mais caracteres que não seja o caracter " e possui o caracter " como último caracter. A segunda expressão considera qualquer caracter entre a e z seguido por qualquer letra, número ou underscore como um identificador. Por último, qualquer caracter que não tenha sido identificado anteriormente é gerado como nome e valor a sua própria representação (e.g., o caracter ( ). É importante notar que, ao reconhecer uma cadeia de caracteres, a ação da direita é tomada imediatamente, ou seja, é emitido um array que possui na primeira posição o nome do token e na segunda posição o valor.
Parser
O Parser atribui contexto aos tokens gerados pelo Lexer. Os parsers são gerados através de uma gramática que define as regras sintáticas da linguagem. Geralmente as gramáticas são definidas utilizando-se a notação Backus Normal Form (BNF), que consiste em um conjunto de regras que descrevem a linguagem. Em outras palavras, define todas as possibilidades de sentenças que podem estar presentes na linguagem. Existem dois tipos de símbolos que são utilizados para expressar uma regra gramatical: terminais e não terminais. O formato de uma regra gramatical pode ser expresso da seguinte forma:
Lado esquerdo -> Lado Direito
Não terminal -> Sequência de terminais e não terminais
Assim como existem ferramentas para gerar o Lexer, também existem ferramentas para gerar o Parser. Para a nossa linguagem utilizaremos o Racc, que é uma implementação do Yacc em Ruby. A forma de expressar uma gramática que o Racc reconhece é similiar ao explicado anteriormente:
NomeDaRegra:
UmRegra TOKEN OutraRegra { result = Node.new }
| UmaRegra { ... }
;
Do lado esquerdo estão os símbolos não terminais e do lado direto estão as sequências de terminais e não terminais. Para cada regra encontrada, o código que está entre chaves é executado. Dessa maneira, a regra gramatical para realizar o parser de uma chamada de método na nossa linguagem 'Caipires' seria a seguinte:
Call:
IDENTIFIER "(" Arguments ")" { result = CallNode.new(nil, val[0], val[2]) }
| Expression "."
IDENTIFIER "(" Arguments ")" { result = CallNode.new(val[0], val[2], val[4]) }
| Expression "." IDENTIFIER { result = CallNode.new(val[0], val[2], []) }
;
Primeiro: no nosso Lado Esquerdo, temos o nome da regra de construção para chamada de métodos (Call). Segundo: nossa chamada de método é composta por um IDENTIFIER (nome do método) seguido de abre parênteses, argumentos e fecha parênteses. Terceiro: podemos ter uma chamada de método composta por uma Expression (e.g., uma variável local) seguida das mesmas regras descritas anteriormente (obj.some_method('param')). Por fim, podemos ter uma chamada de método composta por uma Expression seguida de ponto e IDENTIFIER (obj.some_method). A regra Expression pode ser vista com mais detalhes no repositório da linguagem 'Capires' . É através das regras gramaticais do Parser que as linguagens de programação oferecem os syntax sugar , tentando deixar a linguagem mais simples para o usuário final.
É importante notar que, no exemplo anterior, para cada regra que o Parser consegue identificar é gerado um nó que será adicionado a Abstract Syntax Tree (AST) final, que é a representação do nosso programa em memória. Ou seja, a saída gerada pelo Parser é uma AST que será utilizada posteriormente pelo Interpretador. Aplicando a regra gramatical explicada acima à saída gerada pelo Lexer (array de tokens) anteriormente, nós teriamos o seguinte resultado:
[
<CallNode method='falaso',
arguments=[
<StringNode value='programa teste'>
]
>
]
De uma forma mais visual, a AST ficaria da seguinte maneira:
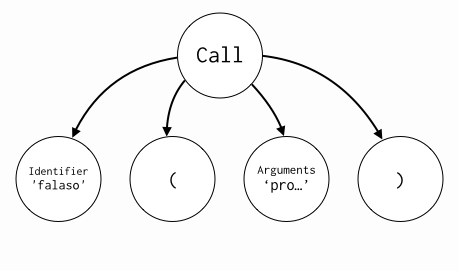
A gramática que acabamos de ver é uma gramática livre de contexto. Segundo Chomsky, existem quatro classes de linguagens formais: recursivamente enumerável, recursiva, livre de contexto e regular. Basicamente, a diferença entre elas são as restrições impostas na hora de se construir uma regra gramatical.
Runtime
Antes de falarmos sobre o Interpretador, precisamos entender o que é o Runtime de uma linguagem. O Runtime demonstra como a linguagem representa seus objetos, métodos, tipos, estruturas na memória, etc. Ou seja, enquanto o Parser determina as regras sintáticas da linguagem, o runtime determina como a linguagem se comporta. Duas linguagens podem ter o mesmo Parser mas possuir um Runtime totalmente diferente. Alguns tópicos precisam ser
avaliados ao analisar o Runtime de uma linguagem: (i) velocidade, (ii) flexibilidade e (iii) utilização de memória.
A velocidade de uma linguagem está ligada à eficiência de seu runtime. Quanto maior for a permissão para que o usuário altere a linguagem, mais poderosa e flexivel ela será. Tudo isso levando-se em consideração a quantidade de memória utilizada. Existem algumas maneiras de modelar o Runtime. A primeira maneira é o Runtime procedural, onde tudo é modelado através de funções (procedures). Não existem objetos e todas as funções compartilham o mesmo namespace, podendo tornar-se difícil gerenciar rapidamente. A linguagem C e PHP (antes da versão 4) utilizam esse modelo de Runtime. A segunda maneira é o Class-Based Runtime, onde as funções são armazenadas em classes e objetos são instancias de classes. O modelo Class-Based é utilizado pela nossa linguagem 'Caipires' e também por outras linguagens, como Ruby, Java, Phyton, etc. É o modelo de Runtime mais popular existente. A terceira maneira é o Prototype-Based, onde tudo é um clone de um objeto e, ao invés de ter classes, os objetos têm um ou mais objetos-pais de onde herdam seus métodos ou atributos. Dessa maneira, os métodos são armazenados diretamente nos objetos. Javascript é um exemplo de linguagem que segue esse modelo de Runtime. Por último, temos o modelo Funcional, onde a computação é tratada como funções matemáticas evitando estado e mutação de dados. Haskell é uma linguagem que utiliza o modelo Funcional no seu Runtime. Por isso, é o Runtime que traz vida à linguagem!
Interpretador
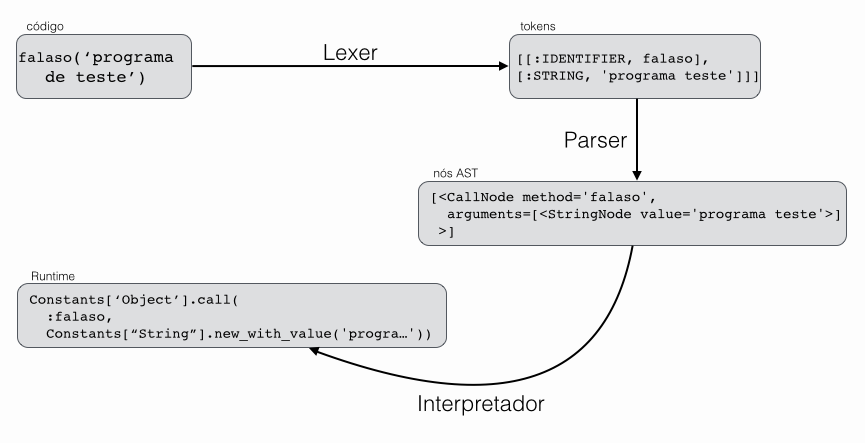
O trabalho do interpretador é interpretar os nós que foram produzidos pelo Parser e modificar o Runtime. Dessa maneira, o Interpretador passa pelos nós da AST gerado pelo Parser e executa (interpreta) a ação correspondente a cada nó, modificando o Runtime. Considere a AST gerada anteriormente. Temos uma chamada ao método falaso passando a string 'programa de teste' como argumento. Como nossa linguaguem possui um Runtime Class-Based, o Interpretador deve chamar o método falaso no objeto corrente e passar como argumento a string 'programa teste' . Todo o processo é ilustrado em seguida:
Máquina Virtual
Na seção anterior foi explicado como o Interpretador caminha pela AST gerada pelo Parser executando a tarefa específica de cada nó para gerar o resultado esperado. Entretanto, este processo não é eficiente e faz com que a linguagem sofra perda de desempenho. Existe ainda a possibilidade da AST consumir grande parte da memória do computador para representar o programa. Torna-se necessária uma forma mais eficiente de realizar a execução do programa. Sendo assim, a Máquina Virtual é um recurso que pode ser utilizado para solucionar os problemas relacionados ao desempenho e consumo de memória.
Um formato eficiente utilizado nas máquinas virtuais é o byte-code. É um formato mais próximo ao código de máquina e, por isso, sua execução é mais rápida que a interpretação da AST gerada pelo Parser. De forma resumida, é um formato similar ao código de máquina que está rodando no seu processador; porém projetado especificamente para uma linguagem. Um byte-code ideal é rápido para compilar a partir do código fonte e rápido para executar, ao mesmo tempo, mantendo o consumo de memória baixo. A portabilidade é outro ponto forte do byte-code, pois ele se mantém o mesmo para diferentes plataformas, necessitando-se apenas que a máquina virtual esteja instalada. Um byte-code, geralmente, é composto por um byte indicando a instrução a ser tomada (opcode) e zero ou mais byte para passagem de parametros (e.g., Java byte-code , Ruby byte-code). Um exemplo pode ser visto a seguir:
#opcode #operando
PUSH_NUMBER = 0 # -> Número para ser colocado na stack
CALL = 2 # -> Método, Número de argumentos
De forma detalhada, o código 0 indica que o número passado deve ser colocado na stack (estrutura utilizada para passagem de parâmetros) e o código 2 indica que o método deve ser invocado com a quantidade de parametros indicada. Já é esperado que os parâmetros tenham sido colocados na stack anteriormente por outras instruções. A máquina virtual utiliza um ponteiro de instruções (Instruction Pointer) para manter mapeado qual instrução deve ser executada. Basicamente, é através do IP que a máquina virtual sabe qual a posição do array de bytes que deve ser executada. Uma observação, o Ruby, antes da versão 1.9, era uma linguagem puramente interpretada. Ou seja, não possuia uma Máquina Virtual e por isso apresentava lentidão na hora de executar o programa. Entretanto, a partir da versão 1.9 o Ruby passou a ser executado através de uma Máquina Virtual (Yarv), ganhando desempenho para executar os programas.
Compilador
O papel do compilador é traduzir o seu código de um formato para outro. Por exemplo: transformar a AST gerada pelo Parser em byte-code para ser executado na Máquina Virtual, transformar o código escrito em SASS para CSS, transformar código escrito em CoffeeScript para Javascript, etc. Dessa maneira, o compilador pode ser utilizado com dois objetivos: (i) compilar para o seu próprio formato e construir um interpretador para interpretar esse formato; (ii) compilar para um formato existente, que pode ser o byte-code da JVM ou até mesmo para código de máquina. Basicamente, o compilador transforma o código da linguagem fonte (i.e., 'Capires') para a linguagem alvo (i.e., código de máquina, JVM byte-code, etc.).
Por trabalharem com o desenvolvimento de software diariamente, é essencial que os desenvolvedores entendam o funcionamento das linguagens de programação. Conhecendo os conceitos e ferramentas utilizados para dar vida aos softwares desenvolvidos, encontramos mais opções para resolvermos os problemas do dia-a-dia de trabalho. Através das explicações apresentadas nesse post, passamos a entender melhor todas as etapas envolvidas no processo de execução de um software, desde a sua escrita até a sua execução pelo computador. Ainda, algumas etapas explicadas anteriormente foram concretizadas na linguagem 'Caipires' para facilitar o entendimento.